Reportings Zabbix avec Jasper
![]()

Aujourd’hui au boulot, je leur ai proposé de faire des rapport sur l’utilisation de Zabbix via l’outil Open source Jasper.
Je vais donc décrire ici les différentes étapes permettant de générer de beaux rapports Jasper pour Zabbix !
J’utilise pour cela jasper Studio en version community (la version open source gratuite).
- Etape 1 : Création du rapport
On va d’abord créer un nouveau rapport Jasper, ainsi qu’un Data Adapter (une connexion a la base de données).
On va utiliser pour cela une connexion jdbc. Il faut alors télécharger le connecteur jdbc correspondant à notre type de base de données (Mysql / Postgres / Oracle, etc..) et renseigner l’url de connexion (ici posgtresql):
JDBC Driver : org.postgresql.Driver
JDBC url : jdbc:postgresql:///zabbix
Username : zabbix
Password :
Attention, il ne faut pas oublier d’ajouter le répertoire dans lequel est stocké le Driver jdbc .jar dans l’onget « Driver Classpath », sinon, ça ne marchera pas.

- Etape 2 : Création du Data Set principal
Ensuite, on va créer le Data Set principal, qui servira a dérouler l’ensemble du rapport.
On sélectionne pour cela le Data Adpater que l’on a créé précédemment et on écrit la requête principale pour le rapport.
Voici ce que j’ai mis pour pouvoir lister toutes les alertes Acquittées pendant la semaine :
SELECT DISTINCT
h.name as host,
g.name as host_group,
t.description as trigger,
a.message,
u.alias
FROM
groups g,
hosts_groups hg,
hosts h,
triggers t,
items i,
functions f,
events e,
acknowledges a,
users u
WHERE
AND g.groupid = hg.groupid
AND hg.hostid = h.hostid
AND e.objectid = t.triggerid
AND t.triggerid = f.triggerid
AND f.itemid = i.itemid
AND i.hostid = h.hostid
AND e.eventid = a.eventid
AND a.userid = u.userid
AND e.value = 1
AND TIMESTAMP 'epoch' + e.clock * INTERVAL '1 second' BETWEEN $P{date_start} AND $P{date_end}
ORDER BY g.name, h.name, t.description
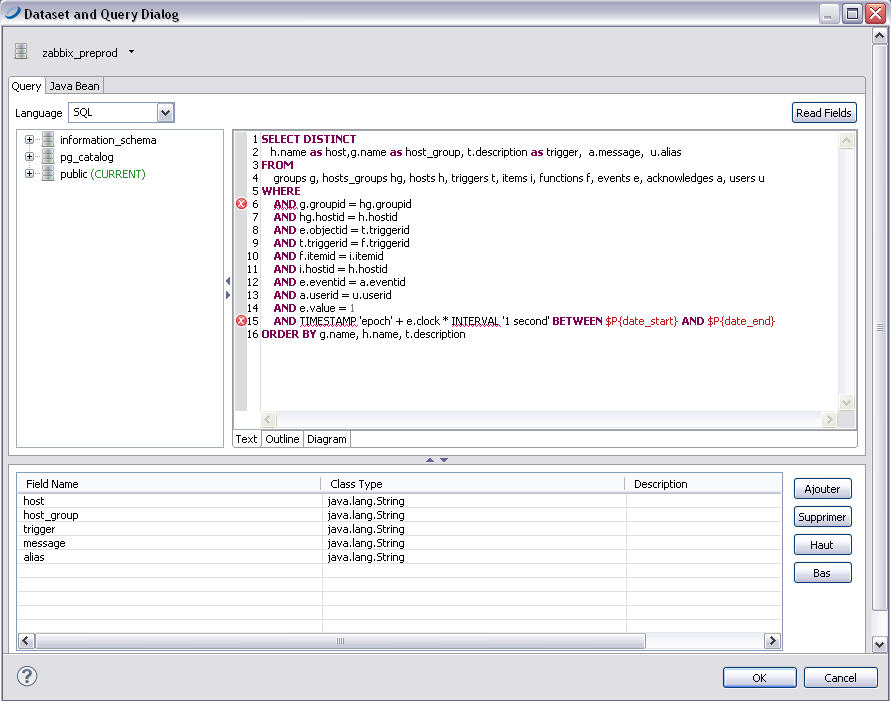
Il faut également penser à ajouter les 2 paramètres date_start et date_end de type java.util.Date dans l’onglet parameters.
- Etape 3 : Layout
Ensuite, on commence par faire un peut de mise en page, avec un titre, un logo, et les dates de début et fin du rapport. J’ai mis un tableau pour contenir le Top 10 des alertes générées, ainsi qu’un camembert pour avoir la répartition des alertes par host.
Ensuite dans les Entêtes de Groupe, de Host, on place les champs $F{host_group} et $F{host} de la requête principale.
Et dans la zone Detail, j’ai mis 3 colonnes avec le nom du trigger, le message d’acquittement et le nom du user qui a acquitté l’alerte.
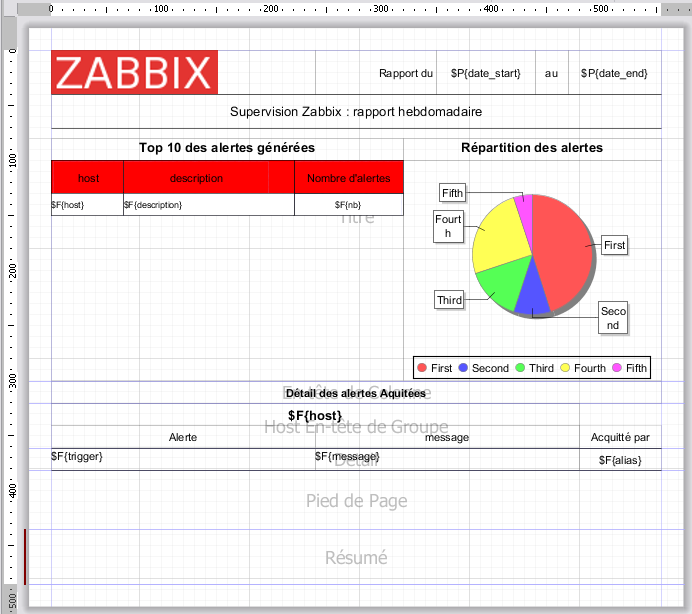
- Etape 4 : Top 10 des Triggers
Pour le Top 10 des alertes, voici ma requête SQL, qu’il faut placer dans un nouveau Data Set :
SELECT
count(DISTINCT e.eventid) as nb,
h.hostid,
h.name as host,
t.triggerid,
t.description
FROM
events e
INNER JOIN triggers t ON t.triggerid = e.objectid
INNER JOIN functions f ON t.triggerid = f.triggerid
INNER JOIN items i ON i.itemid = f.itemid
INNER JOIN hosts h ON h.hostid = i.hostid
WHERE
e.source = 0
AND e.value = 0
AND h.status = 0
AND t.status = 0
AND TIMESTAMP 'epoch' + e.clock * INTERVAL '1 second' BETWEEN $P{date_start} AND $P{date_end}
GROUP BY
h.hostid, h.name, t.triggerid, t.description
ORDER BY nb DESC
LIMIT 10;
Ici aussi, il ne faut pas oublier d’ajouter les parametres date_start et date_end dans l’onglet parameters.
- Etape 5 : Cammembert
Et pour le Pie Chart (le cammembert), j’ai utlisé la requête SQL suivante (encore dans un nouveau Data Set :
SELECT
count(DISTINCT e.eventid) as nb,
h.name as host
FROM
events e
INNER JOIN triggers t ON t.triggerid = e.objectid
INNER JOIN functions f ON t.triggerid = f.triggerid
INNER JOIN items i ON i.itemid = f.itemid
INNER JOIN hosts h ON h.hostid = i.hostid
INNER JOIN hosts_groups hg ON hg.hostid = h.hostid
INNER JOIN groups g ON g.groupid = hg.groupid
WHERE
e.source = 0
AND e.value = 1
AND h.status = 0
AND t.status = 0
AND TIMESTAMP 'epoch' + e.clock * INTERVAL '1 second' BETWEEN $P{date_start} AND $P{date_end}
GROUP BY h.hostid,h.name;
Ici aussi, il ne faut pas oublier d’ajouter les paramètres date_start et date_end dans l’onglet parameters.
Libre a vous d’ajouter des filtre par host group, par user group ou whatever..
- Etape 6 : Mapping des paramètres
Enfin, il ne reste plus qu’a mapper les paramètres de la requête principale dans les Data Set secondaires pour qu’ils soient pris en compte partout. Pour cela, on sélectionne Paramètre dans le menu en bas à droite du tableau ou dans le formulaire Wizard du camembert.
il faut alors associer date_start à $P{date_start} et date_end à $P{date_end}
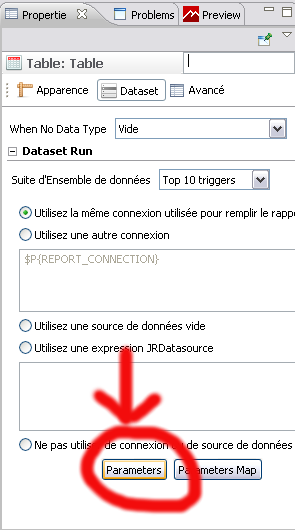
Et voilà ! Il ne reste plus qu’a prévisualiser le tout pour vérifier que cela fonctionne (en général, on a au moins 3 ou 4 java.WTF.Exception) et il faut s’y reprendre a plusieurs fois avant d’arriver a faire marcher le truc.
- Dernière étape : Automatisation !!/li>Comme j’ai pas envie de me prendre la tête avec un jasper Server, et que j’ai juste besoin de lancer mon rapport une fois par semaine, j’ai téléchargé jasperstarter que j’ai installé sur le serveur ou il y a la BDD et il suffit ensuite de le cronner avec les bons paramètres !
Voici les lignes de commande que j’utilise pour compiler et générer le rapport :
Compilation :./jasperstarter/bin/jasperstarter compile path/to/zabbix_A4.jrxml
Génération :
./jasperstarter/bin/jasperstarter process path/to/zabbix_A4.jasper -t postgres -H 127.0.0.1 -u zabbix -p password -n zabbix --db-port 5432 -f pdf -P date_start=2014-02-24 date_end=2014-02-31
Et voila, on obtient un beau PDF avec plein de stats dedans !
bonjour
je teste votre tuto j’en suis à l’étape 2 je dois faire « il faut également penser à ajouter les 2 paramètres date_start et date_end de type java.util.Date dans l’onglet parameters. »
mais ? nota je débute avec jasper studio
Merci
Bonjour,
Il faut ajouter les variables date_start et date_end dans l’outline-> paramètres.
Une fois crée il faut faire un drag and drop des variables crées sur le design.
puis cliquer sur Prévisualiser !!! 🙁 j’obtiens une erreur
net.sf.japerreports.engine.JRException: Error executing SQL Statement….
@+ pour la prochaine étape
Salut,
Ce tuto date un peu (2014), les drivers jasper ont du évoluer depuis.
De plus jasper est un peu démodé. Je te recommande d’utiliser Grafana avec la datasource Zabbix. tu pourras avoir des dashboards en temps réel, beaucoup plus joli qu’avec Jasper.
Hello
in case in use Mysql, which is command in SQL for « …AND TIMESTAMP ‘epoch’ + e.clock * INTERVAL ‘1 second' »
Thank you