Strimzi Kafka Kubernetes Operator
Like I said in my last post about zalando postgresql operator, Kubernetes is a very powerful tool that can be extended with operators to handle new custom resources.
Custom resources can be anything ! A database cluster, a certificate, a prometheus rule or even a Kafka Cluster !
Strimzi operator goal is to deploy and manage kafka clusters inside Kubernetes, but it can also manage a lot of kafka related resources:
- kafka topics
- kafka users
- kafka connectors
- etc..
Installation
First we need to install and configure the strimzi operator in your kubernetes cluster.
One way to install strimzi is to use the helm chart.
kubectl create namespace kafka
helm repo add strimzi https://strimzi.io/charts/
helm -n kafka upgrade --install strimzi strimzi/strimzi-kafka-operatorThis will deploy the strimzi operator and all the kafka custom resources definitions.
Kafka Cluster
Once it is deployed inside our cluster, we can tell strimzi to create a kubernetes cluster for us.
Here is an example of kafka cluster with 3 nodes:
---
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: kafka-cluster
namespace: kafka
spec:
kafka:
replicas: 3
version: 3.3.1
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: scram-sha-512
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 10Gi
deleteClaim: false
jmxOptions: {}
config:
log.message.format.version: "3.3"
inter.broker.protocol.version: "3.3"
offsets.topic.replication.factor: 2
transaction.state.log.replication.factor: 2
transaction.state.log.min.isr: 2
log.roll.hours: 24
max.request.size: 536870912
message.max.bytes: 500000000
num.partitions: 6
default.replication.factor: 1
min.insync.replicas: 1
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: kafka-metrics
key: kafka-metrics-config.yml
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 10Gi
deleteClaim: false
resources:
requests:
cpu: 100m
memory: 512Mi
entityOperator:
topicOperator: {}
userOperator: {}
kafkaExporter: {}As you can see, I’ve configured a zookeeper and a kafka cluster with 3 replicas.
kafka will have 2 listeners. The first one will listen on port 9092 with no TLS or authentication and the second will listen on port 9093 with tls enabled and scram-sha256 authentification.
I’ve also configured persistent storage for each pod and some custom kafka default configuration (partitions, replication, etc..).
And finally I’ve enabled the kafka exporter to expose kafka metrics to prometheus.
It is possible to configure everything ! for example you can configure :
- pod affinities (to ensure kafka pods are on kafka node pool and different nodes)
- resources requests and limits
- jvm options
- custom tls certificates
- etc..
kafka Users
Strimzi kubernetes operator is also capable of managing kafka users and permissions. To do this, you can delclare a KafkaUser resource in your kubernetes cluster and strimzi will automatically configure it in the corresponding cluster.
For example :
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: seuf
labels:
strimzi.io/cluster: kafka-cluster
spec:
authentication:
type: scram-sha-512Once the user is created you will can found his password in the associated kubernetes secret generated by the operator.
Kafka Connect
It is also possible to configure KafkaConnect and KafkaConnector directly with strimzi to replicate your postgresql database into kafka with debezium for example.
Strimzi is able to automatically build a KafkaConnect docker image for you with the plugin you want, but I prefer to build it myself with my CI/CD (gitlab-ci) and push it to my private registry.
Here is an example of Dockerfile to build a kafka connect docker image that can be used with strimzi:
FROM quay.io/strimzi/kafka:0.34.0-kafka-3.4.0
USER root:root
ENV DEBEZIUM_POSTGRESQL_VERSION=2.0.0.Final
ENV KAFKA_KUBERNETES_CONFIG_PROVIDER_VERSION=1.0.1
RUN mkdir -p /opt/kafka/plugins && \
cd /tmp && \
# debzium postgresql plugin
curl -sL https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/${DEBEZIUM_POSTGRESQL_VERSION}/debezium-connector-postgres-${DEBEZIUM_POSTGRESQL_VERSION}-plugin.tar.gz -o debezium-connector-postgres-${DEBEZIUM_POSTGRESQL_VERSION}-plugin.tar.gz && \
tar -xzf debezium-connector-postgres-${DEBEZIUM_POSTGRESQL_VERSION}-plugin.tar.gz && \
mv debezium-connector-postgres /opt/kafka/plugins && \
rm -rf /tmp/debezium-connector-postgres* && \
# kubernetes config plugin
curl -sL https://github.com/strimzi/kafka-kubernetes-config-provider/releases/download/${KAFKA_KUBERNETES_CONFIG_PROVIDER_VERSION}/kafka-kubernetes-config-provider-${KAFKA_KUBERNETES_CONFIG_PROVIDER_VERSION}.tar.gz -o kafka-kubernetes-config-provider-${KAFKA_KUBERNETES_CONFIG_PROVIDER_VERSION}.tar.gz && \
tar -xzf kafka-kubernetes-config-provider-${KAFKA_KUBERNETES_CONFIG_PROVIDER_VERSION}.tar.gz && \
cp kafka-kubernetes-config-provider-${KAFKA_KUBERNETES_CONFIG_PROVIDER_VERSION}/libs/* /opt/kafka/libs/ && \
rm -rf /tmp/kafka-kubernetes-config-provider*
USER 1001
As you can see, I have installed the debezium postgresql connector into the /opt/kafka/plugins folder and the kubernetes-config-provider lib in the /opt/kafka/libs folder.
The strimzi kubernetes config provider will allow me to use kubernetes secrets as source of credentials for my kafka connector configuration.
Once I have builded and pushed my docker image to my private registry, i can use it in a KafkaConnect.yml resource :
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: debezium-connect-cluster
namespace: kafka
annotations:
strimzi.io/use-connector-resources: "true"
spec:
version: 2.6.0
replicas: 1
bootstrapServers: kafka-data.service.malt:9094
image: my.private-docker-registry.io/strimzi-debezium-postgresql:0.34.0-kafka-3.4.0-postgres-2.0.0.Final
logging:
type: inline
loggers:
connect.root.logger.level: "INFO"
config:
config.providers: secrets
config.providers.secrets.class: io.strimzi.kafka.KubernetesSecretConfigProvider
group.id: strimzi-kafkaconnect
offset.storage.topic: strimzi-kafkaconnect-offsets
config.storage.topic: strimzi-kafkaconnect-configs
status.storage.topic: strimzi-kafkaconnect-status
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1
max.request.size: 1048570
producer.max.request.size: 1048570
metricsConfig:
type: jmxPrometheusExporter
valueFrom:
configMapKeyRef:
name: kafka-metrics
key: kafka-connect-metrics-config.yml
template:
pod:
metadata:
labels:
app: kafka-connect-postgresHere I can configure the kafka bootstrap url and the required kafka topics used for kafka connect configuration storage and offset tracking.
I also have added the metricsConfig to allow prometheus scrapping and monitor my connector with grafana dashboards.
The final step is to create a KafkaConnector resource. This will configure the KafkaConnect instance with the required informations to do the change data capture of your source database.
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: debezium-connector-postgresql
namespace: kafka
labels:
strimzi.io/cluster: debezium-connect-cluster
spec:
class: io.debezium.connector.postgresql.PostgresConnector
tasksMax: 1
config:
plugin.name: pgoutput
publication.name: strimzi
slot.name: debezium_strimzi
database.hostname: aperogeek.database.svc
database.port: 5432
database.user: kafkaconnect
database.password: ${secrets:kafka/debezium-secret:postgresql_password}
database.dbname: aperogeek
database.server.name: aperogeek
database.include.list: aperogeek
snapshot.mode: never
heartbeat.interval.ms: 1000
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: connector-configuration-role
namespace: kafka
rules:
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["debezium-secret"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: connector-configuration-role-binding
namespace: kafka
subjects:
- kind: ServiceAccount
name: debezium-connect-cluster-connect
namespace: kafka
roleRef:
kind: Role
name: connector-configuration-role
apiGroup: rbac.authorization.k8s.ioHere I have configured a connector in my kafka connect cluster debezium-connect-cluster .
It will connect to my postgresql database configured in the database namespace and output all the changes into the aperogeek.* kafka topics.
Note that I also have added some RBAC permissions to allow the auto generated service account to access my kubernetes secret containing the database password thanks to the kubernetes config provider previously installed installed in the docker image.
Monitoring
Now we have kafka, kafka connect running in our cluster it’s time to monitor it with prometheus + grafana.
To do that you can declare PodMonitor (another custom resource managed by the prometheus operator). See the official documentation to help you with monitoring setup.
Strimzi provides some example grafana dashboards like this :
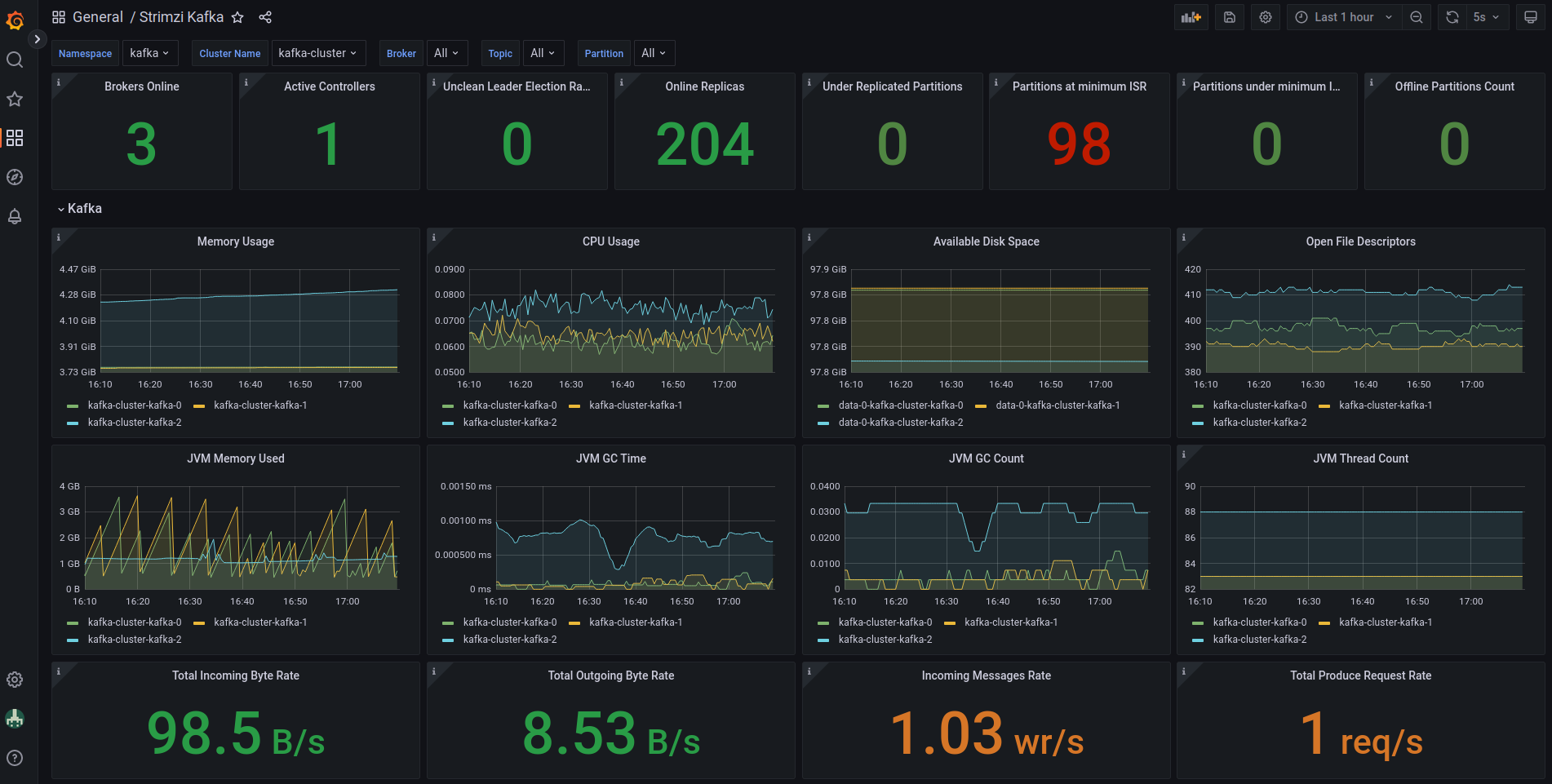
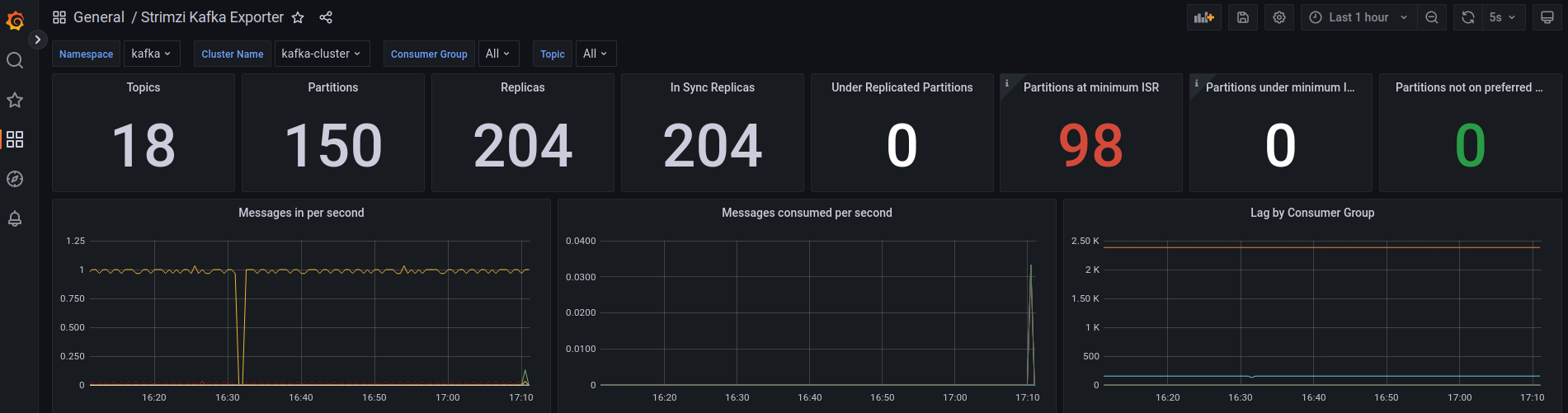
Conclusion
To conclude, I will say that I really like this kubernetes operator. You can manage all the kafka resources with kubectl (useful to patch 200 topics in one bash command 😛 ). The project is really active and well maintained with all new kafka releases.
Strimzi have also introduced the concept of strimziPodSet instead of classic kubernetes StatefulSet. This allow strimzi to have better rolling restart strategy with better auto scaling method (no need for ordered pod restart).
The documentation is very (too) complete and sometimes it’s hard to find the thing you want.
Also it lack of example for kafka resource declaration (kafka connect for example).
Bonus
Here is a small bash script you can cron every 10 minutes with a kube cronjob to detect failed kafka connect tasks and restart it without restarting the whole kafka connect cluster. It happen from times to times, for example if you have a postgresql failover the kafka connect will not automatically reconnect to the new primary.
#!/bin/sh
echo "Fetching tasks"
echo "curl -s \"http://${CONNECT_HOST:-localhost}:${CONNECT_PORT:-8083}/connectors?expand=status\""
tasks=$(curl -s "http://${CONNECT_HOST:-localhost}:${CONNECT_PORT:-8083}/connectors?expand=status")
echo "tasks : "
echo $tasks
tasks_tor_restart=$(echo $tasks | jq -rc -M 'map({name: .status.name } + {tasks: .status.tasks}) | .[] | {task: ((.tasks[]) + {name: .name})} | select(.task.state=="FAILED") | {name: .task.name, task_id: .task.id|tostring} | ("/connectors/"+ .name + "/tasks/" + .task_id + "/restart")')
for t in $tasks_tor_restart; do
echo "Restarting task $t"
echo "curl -X POST \"http://${CONNECT_HOST:-localhost}:${CONNECT_PORT:-8083}${t}\""
curl -X POST "http://${CONNECT_HOST:-localhost}:${CONNECT_PORT:-8083}${t}"
doneOf course you need to install curl and jq in your docker image to make it work.